Comparing local-first frameworks and approaches
Any sufficiently advanced technology is indistinguishable from magic.
Cloud applications can feel like magic. You write text in a Google Doc on your laptop, and it magically appears in the doc on your phone. Or you’re working on some code in an online IDE like Replit, and your entire team can build together.
But, like magic, we all know a lot is going on under the surface that we’re not supposed to see. And, like magic, when it goes wrong, it goes horribly wrong. Such as when you’re writing a Google Doc, the network fails, and the doc hangs. You can’t edit it because the document can’t be updated from the cloud. Suddenly, you wish for Windows 95 and the luxury of local.
Luckily, local isn’t a disappearing technology. In fact, local is making a renaissance with local-first frameworks that put your data in your hands first. If the cloud is there, great. If not, ¯\_(ツ)_/¯. This is such a nascent field that several local-first frameworks are being built to approach this problem from different sides. Here, we want to highlight a few to give you a feel for what to look for in local-first applications.
Merging Data with CRDTs
In 2019, University of Cambridge computer scientist Martin Kleppmann (of Designing Data-Intensive Applications fame) and authors from digital research lab Ink & Switch published a manifesto titled, “Local-first software: you own your data, in spite of the cloud.”
The manifesto laid out their thinking on how the cloud-first data storage model had gone awry. First, you get the issue mentioned above–cloud apps become unusable offline, limiting usability. But the problems go beyond that. When data is stored primarily in the cloud, users become “borrowers” of their own data. The service provider has ultimate control over access and preservation. It can be difficult to migrate data between cloud services, and if the cloud service shuts down, users lose access to their data and work.
The manifesto proposed seven ideals for local-first software:
- No spinners: Fast performance by working with local data
- Multi-device: Seamless sync across all user devices
- Offline: Full read/write functionality without internet access
- Collaboration: Real-time collaborative editing for multiple users
- Longevity: Access and edit data for decades, outliving servers
- Privacy: Encrypted data that’s not accessible to service providers
- User control: Ownership of data, including the ability to copy, modify, and delete
They proposed a number of technical concepts to achieve these aims, with the critical one being the Conflict-Free Replicated Data Type, or CRDT. CRDTs are data structures that allow multiple replicas of a dataset to be updated independently and concurrently without coordination between the replicas while ensuring that all replicas eventually converge to the same state. This makes them particularly well-suited for local-first software architectures. The key properties of CRDTs include:
- Strong eventual consistency. All replicas will converge to the same state given the same set of updates, regardless of order received
- Commutativity. The order of applying updates does not affect the final state
- Associativity. Updates can be grouped and applied in any order
Say you have a collaborative text document that two people are working on. Each can work offline, and CRDTs will take care of merging. They assign unique identifiers to each character or operation, allowing the system to track and merge changes intelligently. For example, if one user inserts text at the beginning of the document while another adds content at the end, the CRDT algorithm can seamlessly integrate both changes without conflict.
Ink & Switch released automerge to automatically achieve this merge. If you have two documents you are collaboratively editing, you can use automerge to make concurrent changes.
import { next as Automerge } from "@automerge/automerge"
let doc = Automerge.from({text: "hello world"})
// Fork the doc and make a change
let forked = Automerge.clone(doc)
forked = Automerge.change(forked, d => {
// Insert ' wonderful' at index 5, don't delete anything
Automerge.splice(d, ["text"], 5, 0, " wonderful")
})
// Make a concurrent change on the original document
doc = Automerge.change(doc, d => {
// Insert at the start, delete 5 characters (the "hello")
Automerge.splice(d, ["text"], 0, 5, "Greetings")
})
// Merge the changes
doc = Automerge.merge(doc, forked)
console.log(doc.text) // "Greetings wonderful world"This approach enables true local-first collaboration, where users can work offline and sync their changes when they reconnect, without the need for a central server to arbitrate conflicts.
Syncing Data with PouchDB
“The Database that Syncs!” shouts the PouchDB homepage. PouchDB is another new local-first/sync database. PouchDB is a JavaScript database that runs in the browser, allowing developers to create applications that work offline and sync with server-side databases when online. It’s designed to be compatible with (and is inspired by) Apache’s NoSQL CouchDB.
The core principles of PouchDB align well with the local-first manifesto:
- Offline-first: Works entirely offline, syncing when a connection is available
- Multi-device sync: Seamlessly syncs data across devices
- Open source: Allows for community contributions and audits
- Cross-platform: Runs in browsers, Node.js, and mobile devices
PouchDB uses a document-based data model, where each document is a JSON object. Here’s a simple example of creating and querying a PouchDB database:
// Create a database
var db = new PouchDB('my_database');
// Add a document
db.put({
_id: 'mittens',
name: 'Mittens',
species: 'cat',
age: 3
}).then(function () {
// Find all documents where species is 'cat'
return db.find({
selector: {species: 'cat'}
});
}).then(function (result) {
console.log(result.docs);
}).catch(function (err) {
console.log(err);
});One of PouchDB’s key features is its sync protocol. When online, PouchDB can sync with a CouchDB server, allowing for real-time collaboration:
var localDB = new PouchDB('my_database');
var remoteDB = new PouchDB('http://example.com/my_database');
localDB.sync(remoteDB, {
live: true,
retry: true
}).on('change', function (change) {
console.log('Data changed:', change);
}).on('error', function (err) {
console.log('Sync error:', err);
});PouchDB doesn’t use CRDTs for conflict resolution. Instead, it uses a deterministic algorithm based on revision history. When conflicts occur, PouchDB chooses a winning revision and stores the others as conflicts, which can be accessed and resolved manually. If you want to nerd out, here’s a good read on how CouchDB provides eventual consistency.
While PouchDB provides a robust solution for offline-first apps, it’s not without challenges. Large datasets can impact performance. And like other local-first solutions, developers need to carefully consider data modeling and conflict resolution strategies.
PouchDB shows us that local-first isn’t just about new, bleeding-edge tech–it’s about reimagining existing databases for a world where offline is the norm, not the exception.
Sync from Postgres with ElectricSQL
ElectricSQL is especially exciting to us at Neon because it uses Postgres as the underlying data store. It is one level broader than a local-first solution: The core component of ElectricSQL is a service called a Sync Engine that runs on your servers between local devices and your Postgres database. So you can use ElectricSQL as a key component of a local-first architecture but it doesn’t solve all your needs.
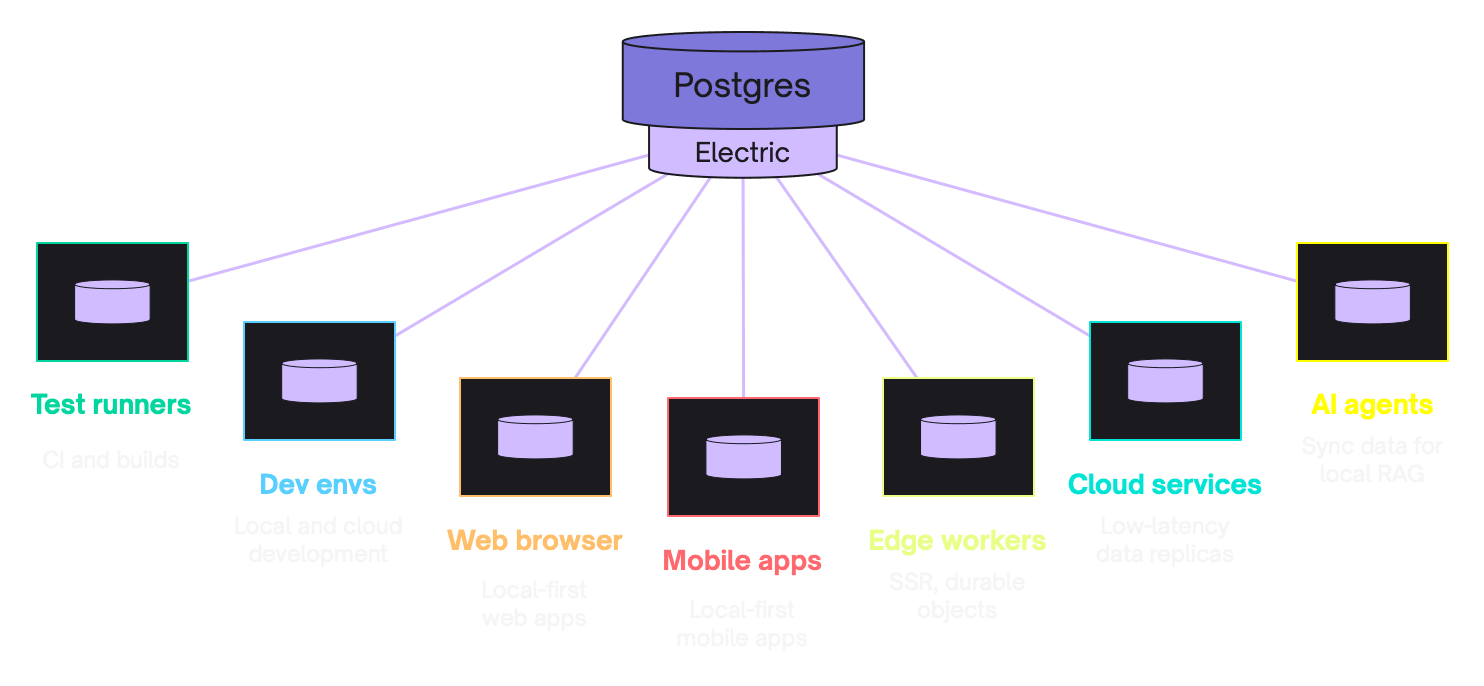
The ElectricSQL service listens for changes in your database using Postgres logical replication and efficiently syncs little subsets of data into connected local apps.
The sync engine is only the server-side component though, you still need a local component to consume the data. ElectricSQL has a Typescript client that gives you basic functionality for consuming data from the sync engine:
import { ShapeStream, Shape } from '@electric-sql/client'
const stream = new ShapeStream({
url: `${BASE_URL}/v1/shape/foo`,
})
const shape = new Shape(stream)
// Returns promise that resolves with the latest shape data once it's fully loaded
await shape.value
// passes subscribers shape data when the shape updates
shape.subscribe(shapeData => {
// shapeData is a Map of the latest value of each row in a shape.
}note
More examples of local-first with ElectricSQL can be found in the examples directory of their repo. https://github.com/electric-sql/electric/tree/main/examples
Local By Default
If you’ve ever wondered how Linear, Figma, or Excalidraw work, this is it. Local-first approaches are changing how we think about data ownership and application architecture. They’re not just solving the offline problem; they’re making us rethink the entire user-data relationship.
This is hardly an exhaustive list. While most local-first frameworks are roughly following one of the above approaches, each has a fun implementation that might make it the best option for you. To take your research further, here’s an evaluation paradigm for assessing local-first solutions, and here’s a list of local-first tools that you can explore. By putting data back in users’ hands, these frameworks are paving the way for more resilient, privacy-respecting, and user-centric applications.